



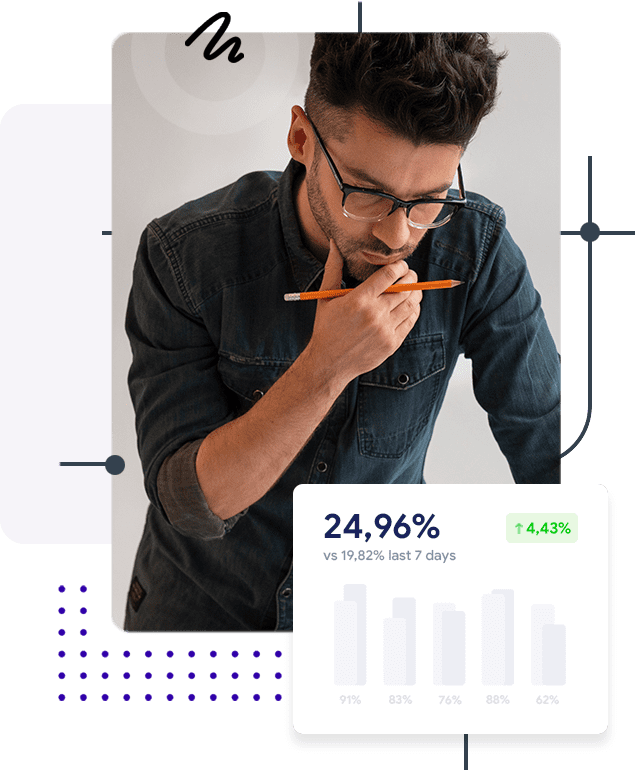



Make the best choice for your LLM application with all cost insights in one place.

Automatically route your requests to the most optimal LLM, balancing performance, cost, and provider limits

Deploy and manage AI models directly in your Kubernetes clusters and join organizations already running secure, self-hosted AI workloads with Cloudtuner.AI.
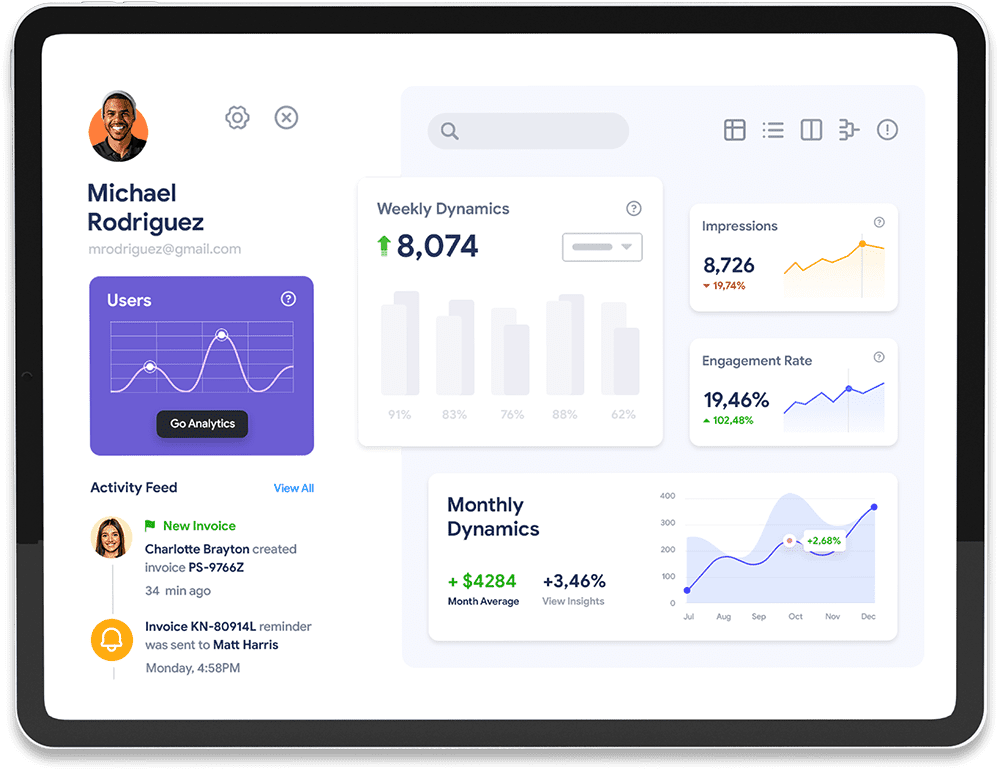
Aliquam a augue suscipit luctus diam neque purus ipsum neque and dolor primis libero


Aliquam a augue suscipit luctus diam neque purus ipsum neque and dolor primis libero
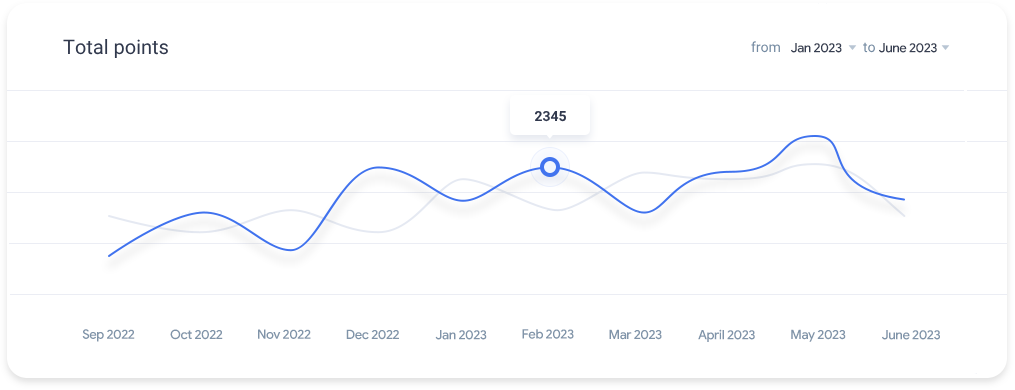
Ligula risus auctor tempus magna feugiat lacinia.
Share findings
Share findings
Share findings
Share findings
Import data
Share findings
Import data
Share findings
Import data
Ligula risus auctor tempus magna feugiat lacinia.
Augue at vitae purus tempus egestas volutpat augue undo cubilia laoreet magna suscipit luctus dolor blandit at purus tempus feugiat impedit

Augue at vitae purus tempus egestas volutpat augue undo cubilia laoreet magna suscipit luctus dolor blandit at purus tempus feugiat impedit

Augue at vitae purus tempus egestas volutpat augue undo cubilia laoreet magna suscipit luctus dolor blandit at purus tempus feugiat impedit

Augue at vitae purus tempus egestas volutpat augue undo cubilia laoreet magna suscipit luctus dolor blandit at purus tempus feugiat impedit
